Le problème n’est pas l’IA. Le problème est la source de ses réponses.
Quiconque utilise aujourd’hui ChatGPT, Gemini ou des outils similaires en entreprise constate tôt ou tard : l’IA répond rapidement, avec fluidité – et parfois simplement de manière incorrecte. Elle invente des chiffres. Elle cite des sources qui n’existent pas. Elle décrit des produits ou des processus obsolètes ou jamais exacts. Ce phénomène a un nom : l’hallucination. Et il a une cause technique.
Comment fonctionne l’IA standard – et pourquoi elle hallucine
Un modèle de langage comme GPT-4 est entraîné sur un immense corpus de textes. Cet ensemble de données a une date de fin fixe. Ce qui s’est passé après, le modèle ne le sait pas. Ce qui s’applique dans votre organisation – tarifs actuels, règlements, produits – ne figure nulle part dans ses données d’entraînement.
Quand vous interrogez quand même le modèle, il répond quand même. Il extrapole. Il devine. Il semble confiant, car les modèles de langage ne signalent pas l’incertitude quand ils ne le devraient pas.
Des études montrent : pour les questions factuelles, les modèles de langage actuels hallucinent dans 15 à 25 pourcent des cas. Cela semble abstrait – jusqu’à ce qu’on considère ce que cela signifie dans un contexte professionnel.
Un exemple concret : Une caisse de pension déploie un chatbot IA standard. Un assuré demande le taux de conversion actuel. Le modèle répond avec une valeur issue de ses données d’entraînement – qui n’est plus valable depuis deux ans. L’assuré planifie sa retraite sur la base d’un chiffre erroné. La différence peut représenter plusieurs milliers de francs de rente annuelle.
La même situation se produit pour les services RH avec des règlements de congés modifiés, pour les équipes juridiques avec des directives de conformité révisées, et pour les services clients avec de nouveaux tarifs de produits.
L’hallucination n’est pas un bug. C’est le comportement d’un système optimisé pour la probabilité – pas pour la vérité.
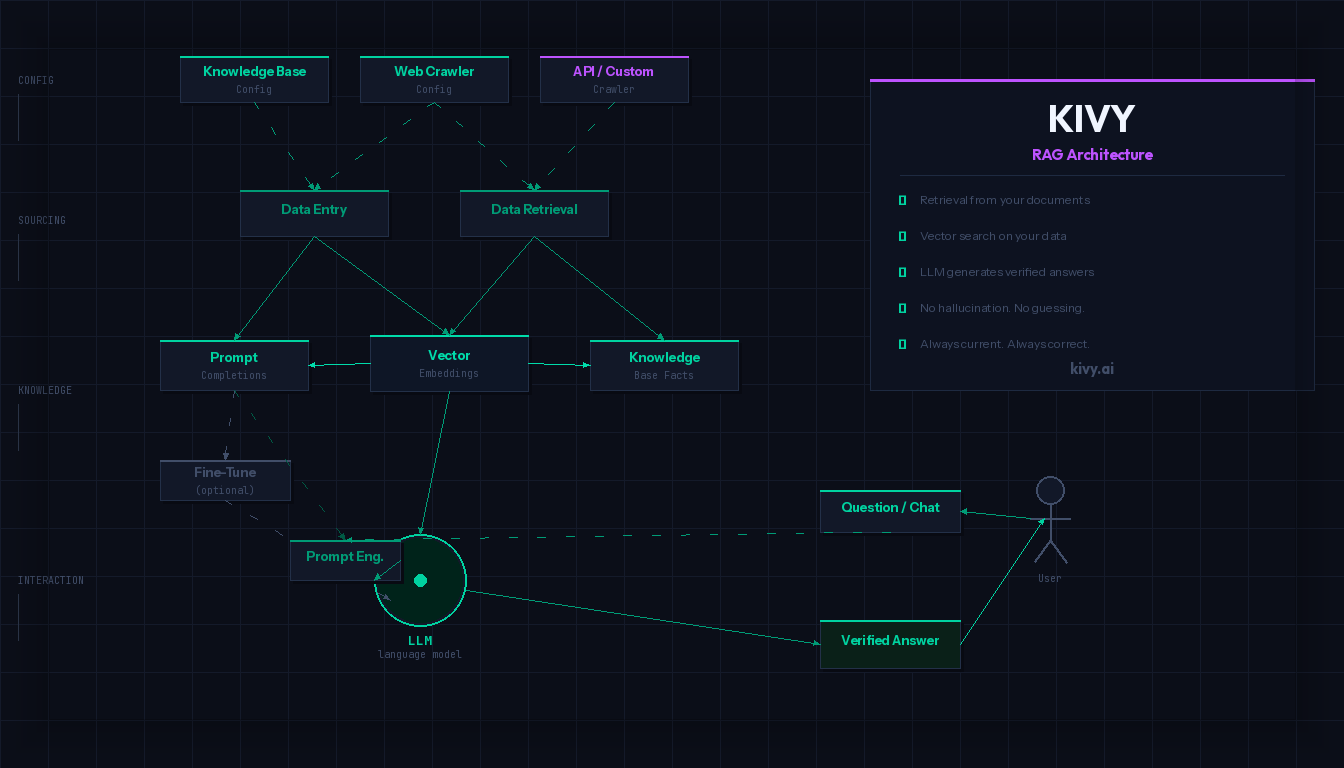
Ce que RAG fait différemment
RAG signifie Retrieval Augmented Generation. L’approche est conceptuellement simple – et change tout.
Au lieu de répondre directement à partir des connaissances d’entraînement, un système RAG effectue d’abord une recherche ciblée : dans vos propres documents, manuels, bases de données et systèmes de connaissances. Ce n’est qu’une fois les informations pertinentes trouvées et vérifiées que le modèle de langage formule une réponse – sur la base de ces sources concrètes.
Le principe en trois étapes :
| Étape | Ce qui se passe |
|---|---|
| 1. Retrieve | Le système recherche dans vos documents les contenus pertinents |
| 2. Augment | Les informations trouvées sont transmises au modèle comme contexte |
| 3. Generate | Le modèle formule une réponse – exclusivement sur la base de ces sources |
Le modèle n’invente rien. Il résume ce qui figure réellement dans vos documents. Et comme vous contrôlez les documents, vous pouvez vérifier à tout moment la provenance d’une réponse.
IA standard vs. RAG : La comparaison directe
| Dimension | IA standard (ex. ChatGPT) | Système RAG (ex. KIVY) |
|---|---|---|
| Source de données | Données d’entraînement (date limite) | Vos documents actuels |
| Actualité | Obsolète après l’entraînement | Toujours à jour |
| Traçabilité | Aucune attribution de source possible | Chaque réponse est basée sur des sources |
| Risque d’hallucination | 15–25 % pour les questions factuelles | Fortement réduit grâce au grounding |
| Contexte organisationnel | Absent | Entièrement intégré |
| Contrôlabilité | Aucune | Contenu modifiable à tout moment |
Comment KIVY met cela en pratique
KIVY est une plateforme basée sur RAG pour les organisations qui souhaitent déployer l’IA de manière productive et fiable. Le système connecte un modèle de langage à la base de connaissances propre de l’organisation – qu’il s’agisse de contenus web, de documents internes, de bases de données produits ou de référentiels de connaissances structurés.
Un scénario concret : Une organisation disposant de 600 documents internes – règlements, FAQs, informations produits, descriptions de processus – les connecte via KIVY à un modèle de langage. Les collaborateurs ou les clients posent des questions en langage naturel. KIVY recherche d’abord dans les 600 documents, identifie les sections les plus pertinentes et les transmet au modèle comme contexte. La réponse provient exclusivement de ces sources – avec attribution de source, traçable et modifiable.
Cas d’usage typiques :
- Service client : Chatbots qui répondent correctement aux questions sur les informations produits, les tarifs et les FAQs
- Caisses de pension et assurances : Réponses juridiquement sûres basées sur les règlements en vigueur
- RH et intranet : Les collaborateurs reçoivent des réponses correctes aux questions sur les politiques internes
- Éducation et administration publique : Services aux citoyens et conseil aux étudiants sans désinformation
Ce n’est pas du marketing. C’est de l’architecture.
La différence entre l’IA standard et RAG n’est pas une fonctionnalité qu’on peut activer ou désactiver. C’est une question fondamentale d’architecture système.
L’IA standard est un système fermé. Elle sait ce qu’elle a appris lors de l’entraînement – et comble les lacunes avec des probabilités. RAG est un système ouvert. Il connecte le modèle de langage à une base de connaissances actuelle et vérifiable.
Pour les organisations qui veulent exploiter l’IA de manière productive et non juste la démontrer, cette différence est décisive. Une mauvaise réponse à un client, une base juridique hallucinée, un prix de produit inventé : ce ne sont pas des risques théoriques. Ce sont des situations qui se produisent quotidiennement lorsque l’IA est déployée sans ancrage.
Questions fréquentes sur RAG
Que signifie RAG ? RAG signifie Retrieval Augmented Generation. C’est une architecture IA dans laquelle un modèle de langage récupère des informations pertinentes depuis une base de connaissances externe avant de générer une réponse.
Pourquoi ChatGPT hallucine-t-il ? ChatGPT et autres modèles de langage sont entraînés sur la probabilité, pas sur la vérification des faits. Sans accès à des sources actuelles et vérifiées, ils comblent les lacunes de connaissances avec des informations plausibles mais potentiellement incorrectes.
Quelle est la différence entre RAG et le fine-tuning ? Le fine-tuning adapte le modèle lui-même – c’est complexe, coûteux et devient obsolète avec le temps. RAG connecte un modèle non modifié à une base de connaissances externe maintenue à jour. Pour la plupart des applications professionnelles, RAG est le choix le plus pragmatique et le plus sûr.
Quelle est l’actualité des réponses dans un système RAG ? Aussi actuelle que les documents que vous stockez dans le système. Vous contrôlez la base de connaissances – et donc l’exactitude des réponses.
Conclusion
L’hallucination ne peut pas être résolue avec de meilleures instructions. C’est une caractéristique structurelle des modèles de langage sans ancrage. RAG résout ce problème au niveau architectural : l’IA ne répond plus à l’intuition – mais à partir de vos données. Toujours exact. Toujours traçable. Toujours actuel.
Quiconque veut utiliser l’IA sérieusement en entreprise ne peut pas éviter RAG.