The problem isn’t the AI. The problem is where it gets its answers from.
Anyone using ChatGPT, Gemini or similar tools in business today will notice sooner or later: the AI responds quickly, fluently – and sometimes simply wrong. It invents numbers. It cites sources that don’t exist. It describes products or processes that are outdated or were never accurate. This phenomenon has a name: hallucination. And it has a technical cause.
How standard AI works – and why it hallucinates
A language model like GPT-4 is trained on a massive text corpus. That dataset has a fixed end date. What happened after that, the model doesn’t know. What applies in your organisation – current rates, policies, products – is nowhere in its training data.
When you ask the model anyway, it answers anyway. It extrapolates. It guesses. It sounds confident doing so, because language models don’t signal uncertainty when they think they shouldn’t.
Research shows: for factual questions, current language models hallucinate in 15 to 25 percent of cases. That sounds abstract – until you consider what it means in a business context.
A concrete example: A pension fund deploys a standard AI chatbot. A member asks about the current conversion rate. The model answers with a value from its training data – one that’s been outdated for two years. The member plans their retirement based on a wrong number. The difference can amount to several thousand francs in annual pension payments.
The same applies to HR departments with updated holiday policies, legal teams with revised compliance guidelines, and customer service teams with new product pricing.
Hallucination isn’t a bug. It’s the behaviour of a system optimised for probability – not for truth.
What RAG does differently
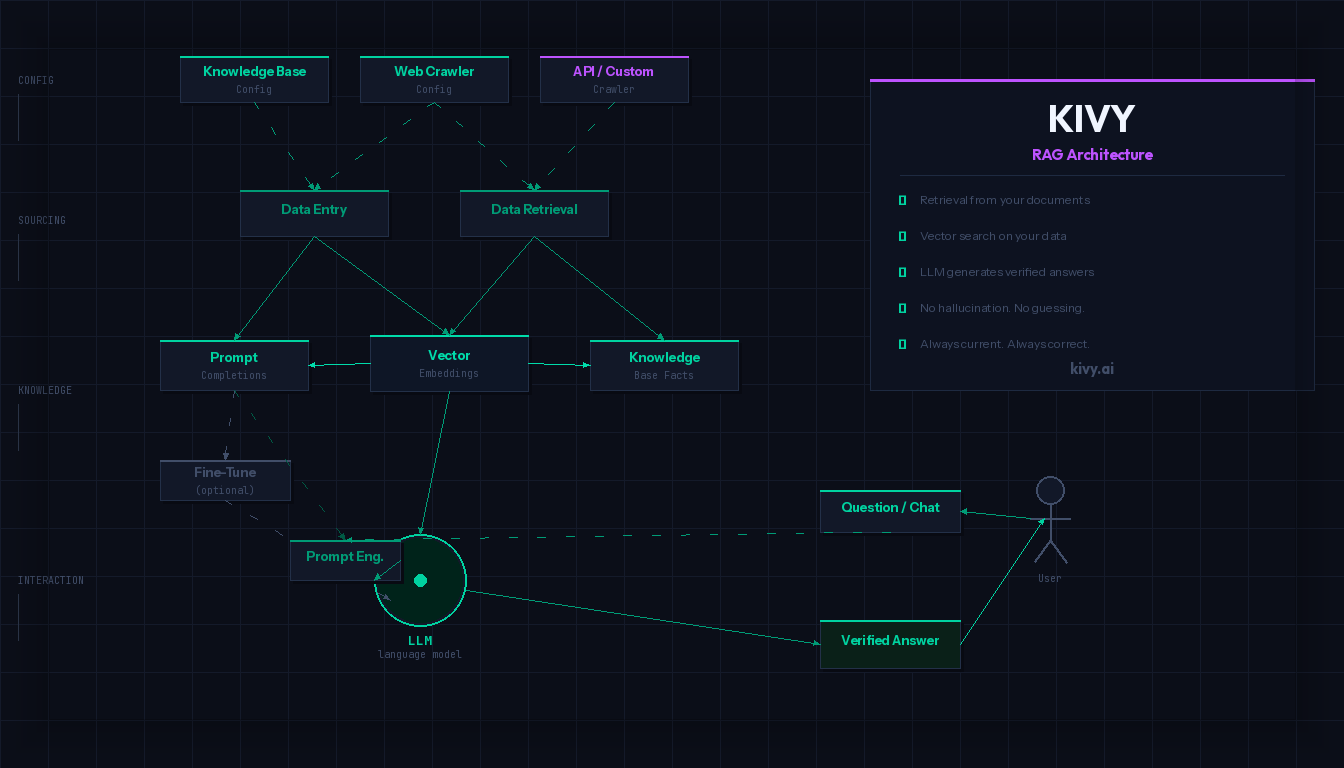
RAG stands for Retrieval Augmented Generation. The approach is conceptually simple – and changes everything.
Instead of answering directly from training knowledge, a RAG system first performs a targeted search: in your own documents, manuals, databases, and knowledge systems. Only when the relevant information has been found and verified does the language model formulate an answer – based on these concrete sources.
The principle in three steps:
| Step | What happens |
|---|---|
| 1. Retrieve | The system searches your own documents for relevant content |
| 2. Augment | The found information is passed to the language model as context |
| 3. Generate | The model formulates an answer – exclusively based on these sources |
The model invents nothing. It summarises what is actually in your documents. And because you control the documents, you can verify at any time where an answer comes from.
Standard AI vs. RAG: The direct comparison
| Dimension | Standard AI (e.g. ChatGPT) | RAG system (e.g. KIVY) |
|---|---|---|
| Data source | Training data (fixed cutoff) | Your current documents |
| Currency | Outdated after training | Always up to date |
| Traceability | No source attribution possible | Every answer is source-based |
| Hallucination risk | 15–25% for factual questions | Strongly reduced through grounding |
| Business context | Not present | Fully integrated |
| Controllability | None | Content updatable at any time |
How KIVY implements this in practice
KIVY is a RAG-based platform for organisations that want to deploy AI productively and reliably. The system connects a language model with the organisation’s own knowledge base – whether website content, internal documents, product databases or structured knowledge repositories.
A concrete scenario: An organisation with 600 internal documents – policies, FAQs, product information, process descriptions – connects these via KIVY to a language model. Employees or customers ask questions in natural language. KIVY first searches the 600 documents, identifies the most relevant sections and passes them to the language model as context. The answer comes exclusively from these sources – with source attribution, traceable, and updatable.
Typical use cases:
- Customer service: Chatbots that correctly answer questions about current product information, pricing and FAQs
- Pension funds and insurers: Legally sound answers based on current regulations
- HR and intranet: Employees receive correct answers to policy questions
- Education and public administration: Citizen services and student advising without misinformation
This isn’t marketing. It’s architecture.
The difference between standard AI and RAG isn’t a feature you can switch on or off. It’s a fundamental question of system architecture.
Standard AI is a closed system. It knows what it learned during training – and fills gaps with probabilities. RAG is an open system. It connects the language model with a current, verifiable knowledge base.
For organisations that want to operate AI productively rather than just demonstrate it, this difference is critical. A wrong answer to a customer, a hallucinated legal basis, an invented product price: these aren’t theoretical risks. These are situations that happen daily when AI is deployed without grounding.
Frequently asked questions about RAG
What does RAG mean? RAG stands for Retrieval Augmented Generation. It’s an AI architecture in which a language model retrieves relevant information from an external knowledge base before generating an answer.
Why does ChatGPT hallucinate? ChatGPT and other language models are trained on probability, not fact-checking. Without access to current, verified sources, they fill knowledge gaps with plausible-sounding but potentially incorrect information.
What’s the difference between RAG and fine-tuning? Fine-tuning adapts the model itself – it’s complex, expensive and becomes outdated over time. RAG connects an unmodified model with an externally maintained, current knowledge base. For most business applications, RAG is the more pragmatic and safer choice.
How current are answers in a RAG system? As current as the documents you store in the system. You control the knowledge base – and therefore the accuracy of the answers.
Conclusion
Hallucination cannot be solved with better prompts. It’s a structural characteristic of language models without grounding. RAG solves this problem at the architecture level: the AI no longer answers from gut instinct – but from your data. Always accurate. Always traceable. Always current.
Anyone who wants to use AI seriously in business cannot avoid RAG.